What Is A Decision Tree ? How Does It Work ?
Intro
Decision tree is a type of supervised learning algorithm (having a pre-defined target variable) that is mostly used in classification problems. It works for both categorical and continuous input and output variables. In this technique, the population or sample are split into two or more homogeneous sets (or sub-populations) based on most significant splitter differentiator in input variables.
Example
Say we have a sample of 30 students with three variables: Gender (Boy/Girl), Class(IX/X) and Height (5 to 6 ft). 15 out of these 30 play cricket in leisure time. Now, we want to create a model to predict who will play cricket during leisure period? In this problem, we need to segregate students who play cricket in their leisure time based on highly significant input variable among all three.
This is where decision tree helps, it will segregate the students based on all values of three variables and identify the variable, which creates the best homogeneous sets of students (which are heterogeneous to each other). In the snapshot below, you can see that variable Gender is able to identify best homogeneous sets compared to the other two variables.
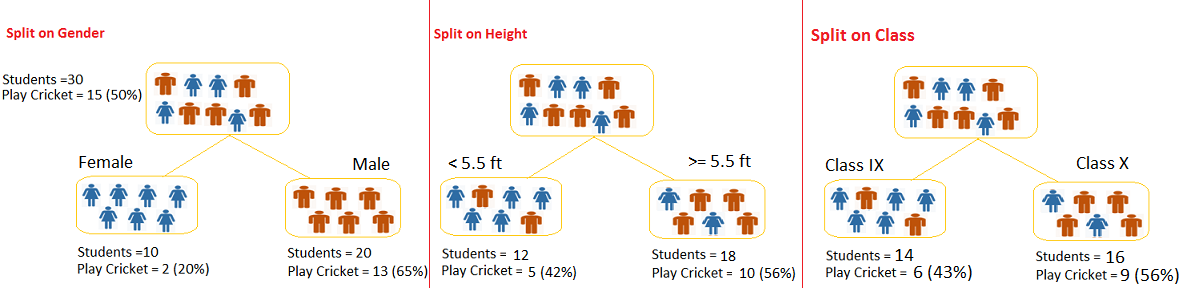
As mentioned above, decision tree identifies the most significant variable and its value that gives best homogeneous sets of population. Now the question which arises is, how does it identify the variable and the split? To do this, decision tree uses various algorithms, which we will shall discuss in the following section.
Types of Decision Trees
Types of decision tree are based on the type of target variable we have. It can be of two types:
1) Categorical Variable Decision Tree
This type of Decision Tree which has categorical target variable then it called as categorical variable decision tree. E.g., in above scenario of student problem, where the target variable was “Student will play cricket or not” i.e. YES or NO.
2) Continuous Variable Decision Tree
This type of Decision Tree has continuous target variable then it is called as Continuous Variable Decision Tree.
Example
Let’s say we have a problem to predict whether a customer will pay his renewal premium with an insurance company (yes/no). Here we know that income of a customer is a significant variable but insurance company does not have income details for all customers. Now, as we know this is an important variable, then we can build a decision tree to predict customer income based on occupation, age and various other variables. In this case, we are predicting values for continuous variable.
Important Terminology
Let’s look at the basic terminology used with Decision trees:
1) Root Node
It represents entire population or sample and this further gets divided into two or more homogeneous sets.
2) Splitting
It is a process of dividing a node into two or more sub-nodes.
3) Decision Node
When a sub-node splits into further sub-nodes, then it is called decision node.
4) Leaf/Terminal Node
Nodes do not split is called Leaf or Terminal node.
5) Pruning
When we remove sub-nodes of a decision node, this process is called pruning. You can say opposite process of splitting.
6) Branch/Sub-Tree
A sub section of entire tree is called branch or sub-tree.
7) Parent and Child Node
A node, which is divided into sub-nodes is called parent node of sub-nodes where as sub-nodes are the child of parent node.

These above are the terms commonly used for decision trees. As we know that every algorithm has advantages and disadvantages, below are the important factors which one should know.
Advantages
1) Easy to Understand
Decision tree output is very easy to understand even for people from non-analytical background. It does not require any statistical knowledge to read and interpret them. Its graphical representation is very intuitive and users can easily relate their hypothesis.
2) Useful in Data Exploration
Decision tree is one of the fastest way to identify most significant variables and relation between two or more variables. With the help of decision trees, we can create new variables/features that has better power to predict target variable. For example, we are working on a problem where we have information available in hundreds of variables, there decision tree will help to identify most significant variable.
3) Less Data Cleaning Required
It requires less data cleaning compared to some other modeling techniques. It is not influenced by outliers and missing values to a fair degree.
4) Data Type Is Not a Constraint
It can handle both numerical and categorical variables.
5) Non Parametric Method
Decision tree is considered to be a non-parametric method. This means that decision trees have no assumptions about the space distribution and the classifier structure.
Disadvantages
1) Over Fitting
Over fitting is one of the most practical difficulty for decision tree models. This problem gets solved by setting constraints on model parameters and pruning (discussed in detailed below).
2) Not Fit for Continuous Variables
While working with continuous numerical variables, decision tree looses information when it categorizes variables in different categories.
Decision-Tree, Tree — Apr 15, 2018
Search
Made with ❤️ and ☀️ on Earth.